|
SNAP Library 2.3, Developer Reference
2014-06-16 11:58:46
SNAP, a general purpose, high performance system for analysis and manipulation of large networks
|
|
SNAP Library 2.3, Developer Reference
2014-06-16 11:58:46
SNAP, a general purpose, high performance system for analysis and manipulation of large networks
|
#include <unicode.h>

Classes | |
| class | TSubcatHelper |
| class | TUcdFileReader |
Public Types | |
| enum | { HangulSBase = 0xAC00, HangulLBase = 0x1100, HangulVBase = 0x1161, HangulTBase = 0x11A7, HangulLCount = 19, HangulVCount = 21, HangulTCount = 28, HangulNCount = HangulVCount * HangulTCount, HangulSCount = HangulLCount * HangulNCount } |
| enum | TCaseConversion_ { ccLower = 0, ccUpper = 1, ccTitle = 2, ccMax = 3 } |
| typedef enum TUniChDb::TCaseConversion_ | TCaseConversion |
Public Member Functions | |
| TUniChDb () | |
| TUniChDb (TSIn &SIn) | |
| void | Clr () |
| void | Save (TSOut &SOut) const |
| void | Load (TSIn &SIn) |
| void | LoadBin (const TStr &fnBin) |
| void | Test (const TStr &basePath) |
| const TStr & | GetScriptName (const int scriptId) const |
| int | GetScriptByName (const TStr &scriptName) const |
| int | GetScript (const TUniChInfo &ci) const |
| int | GetScript (const int cp) const |
| const char * | GetCharName (const int cp) const |
| TStr | GetCharNameS (const int cp) const |
| template<class TSrcVec > | |
| void | PrintCharNames (FILE *f, const TSrcVec &src, size_t srcIdx, const size_t srcCount, const TStr &prefix) const |
| template<class TSrcVec > | |
| void | PrintCharNames (FILE *f, const TSrcVec &src, const TStr &prefix) const |
| bool | IsGetChInfo (const int cp, TUniChInfo &ChInfo) |
| TUniChCategory | GetCat (const int cp) const |
| TUniChSubCategory | GetSubCat (const int cp) const |
| bool | IsWbFlag (const int cp, const TUniChFlags flag) const |
| int | GetWbFlags (const int cp) const |
| bool | IsSbFlag (const int cp, const TUniChFlags flag) const |
| int | GetSbFlags (const int cp) const |
| DECLARE_FORWARDED_PROPERTY_METHODS bool | IsPrivateUse (const int cp) const |
| bool | IsSurrogate (const int cp) const |
| int | GetCombiningClass (const int cp) const |
| template<typename TSrcVec > | |
| bool | FindNextWordBoundary (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, size_t &position) const |
| template<typename TSrcVec > | |
| void | FindWordBoundaries (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, TBoolV &dest) const |
| template<typename TSrcVec > | |
| bool | FindNextSentenceBoundary (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, size_t &position) const |
| template<typename TSrcVec > | |
| void | FindSentenceBoundaries (const TSrcVec &src, const size_t srcIdx, const size_t srcCount, TBoolV &dest) const |
| void | SbEx_Clr () |
| template<class TSrcVec > | |
| void | SbEx_Add (const TSrcVec &v) |
| void | SbEx_Add (const TStr &s) |
| void | SbEx_AddUtf8 (const TStr &s) |
| int | SbEx_AddMulti (const TStr &words, const bool wordsAreUtf8=true) |
| void | SbEx_Set (const TUniTrie< TInt > &newTrie) |
| int | SbEx_SetStdEnglish () |
| template<typename TSrcVec , typename TDestCh > | |
| void | Decompose (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | Decompose (const TSrcVec &src, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | Compose (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | Compose (const TSrcVec &src, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | DecomposeAndCompose (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | DecomposeAndCompose (const TSrcVec &src, TVec< TDestCh > &dest, bool compatibility, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| size_t | ExtractStarters (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| size_t | ExtractStarters (const TSrcVec &src, TVec< TDestCh > &dest, bool clrDest=true) const |
| template<typename TSrcVec > | |
| size_t | ExtractStarters (TSrcVec &src) const |
| void | LoadTxt (const TStr &basePath) |
| void | SaveBin (const TStr &fnBinUcd) |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetCaseConverted (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest, const TCaseConversion how, const bool turkic, const bool lithuanian) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetLowerCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetUpperCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetTitleCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetLowerCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetUpperCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetTitleCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool turkic=false, const bool lithuanian=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleCaseConverted (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest, const TCaseConversion how) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleLowerCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleUpperCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleTitleCase (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleLowerCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleUpperCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetSimpleTitleCase (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true) const |
| template<typename TSrcVec > | |
| void | ToSimpleCaseConverted (TSrcVec &src, size_t srcIdx, const size_t srcCount, const TCaseConversion how) const |
| template<typename TSrcVec > | |
| void | ToSimpleUpperCase (TSrcVec &src, size_t srcIdx, const size_t srcCount) const |
| template<typename TSrcVec > | |
| void | ToSimpleLowerCase (TSrcVec &src, size_t srcIdx, const size_t srcCount) const |
| template<typename TSrcVec > | |
| void | ToSimpleTitleCase (TSrcVec &src, size_t srcIdx, const size_t srcCount) const |
| template<typename TSrcVec > | |
| void | ToSimpleUpperCase (TSrcVec &src) const |
| template<typename TSrcVec > | |
| void | ToSimpleLowerCase (TSrcVec &src) const |
| template<typename TSrcVec > | |
| void | ToSimpleTitleCase (TSrcVec &src) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetCaseFolded (const TSrcVec &src, size_t srcIdx, const size_t srcCount, TVec< TDestCh > &dest, const bool clrDest, const bool full, const bool turkic=false) const |
| template<typename TSrcVec , typename TDestCh > | |
| void | GetCaseFolded (const TSrcVec &src, TVec< TDestCh > &dest, const bool clrDest=true, const bool full=true, const bool turkic=false) const |
| template<typename TSrcVec > | |
| void | ToCaseFolded (TSrcVec &src, size_t srcIdx, const size_t srcCount, const bool turkic=false) const |
| template<typename TSrcVec > | |
| void | ToCaseFolded (TSrcVec &src, const bool turkic=false) const |
Static Public Member Functions | |
| static TStr | GetCaseFoldingFn () |
| static TStr | GetSpecialCasingFn () |
| static TStr | GetUnicodeDataFn () |
| static TStr | GetCompositionExclusionsFn () |
| static TStr | GetScriptsFn () |
| static TStr | GetDerivedCorePropsFn () |
| static TStr | GetLineBreakFn () |
| static TStr | GetPropListFn () |
| static TStr | GetAuxiliaryDir () |
| static TStr | GetWordBreakTestFn () |
| static TStr | GetWordBreakPropertyFn () |
| static TStr | GetSentenceBreakTestFn () |
| static TStr | GetSentenceBreakPropertyFn () |
| static TStr | GetNormalizationTestFn () |
| static TStr | GetBinFn () |
| static TStr | GetScriptNameUnknown () |
| static TStr | GetScriptNameKatakana () |
| static TStr | GetScriptNameHiragana () |
Protected Types | |
| typedef TUniVecIdx | TVecIdx |
Protected Member Functions | |
| void | InitAfterLoad () |
| bool | IsWbIgnored (const int cp) const |
| template<typename TSrcVec > | |
| void | WbFindCurOrNextNonIgnored (const TSrcVec &src, size_t &position, const size_t srcEnd) const |
| template<typename TSrcVec > | |
| void | WbFindNextNonIgnored (const TSrcVec &src, size_t &position, const size_t srcEnd) const |
| template<typename TSrcVec > | |
| void | WbFindNextNonIgnoredS (const TSrcVec &src, size_t &position, const size_t srcEnd) const |
| template<typename TSrcVec > | |
| bool | WbFindPrevNonIgnored (const TSrcVec &src, const size_t srcStart, size_t &position) const |
| void | TestWbFindNonIgnored (const TIntV &src) const |
| void | TestWbFindNonIgnored () const |
| void | TestFindNextWordOrSentenceBoundary (const TStr &basePath, bool sentence) |
| template<typename TSrcVec > | |
| bool | CanSentenceEndHere (const TSrcVec &src, const size_t srcIdx, const size_t position) const |
| template<typename TDestCh > | |
| void | AddDecomposition (const int codePoint, TVec< TDestCh > &dest, const bool compatibility) const |
| void | TestComposition (const TStr &basePath) |
| void | InitWordAndSentenceBoundaryFlags (const TStr &basePath) |
| void | InitScripts (const TStr &basePath) |
| void | InitLineBreaks (const TStr &basePath) |
| void | InitDerivedCoreProperties (const TStr &basePath) |
| void | InitPropList (const TStr &basePath) |
| void | InitSpecialCasing (const TStr &basePath) |
| void | LoadTxt_ProcessDecomposition (TUniChInfo &ci, TStr s) |
| void | TestCaseConversion (const TStr &source, const TStr &trueLc, const TStr &trueTc, const TStr &trueUc, bool turkic, bool lithuanian) |
| void | TestCaseConversions () |
Static Protected Member Functions | |
| static bool | IsWbIgnored (const TUniChInfo &ci) |
Protected Attributes | |
| TUniTrie< TInt > | sbExTrie |
Friends | |
| class | TUniCaseFolding |
| typedef enum TUniChDb::TCaseConversion_ TUniChDb::TCaseConversion |
|
protected |
| anonymous enum |
| Enumerator | |
|---|---|
| HangulSBase | |
| HangulLBase | |
| HangulVBase | |
| HangulTBase | |
| HangulLCount | |
| HangulVCount | |
| HangulTCount | |
| HangulNCount | |
| HangulSCount | |
Definition at line 1405 of file unicode.h.
| Enumerator | |
|---|---|
| ccLower | |
| ccUpper | |
| ccTitle | |
| ccMax | |
Definition at line 1584 of file unicode.h.
|
inline |
|
inlineexplicit |
|
protected |
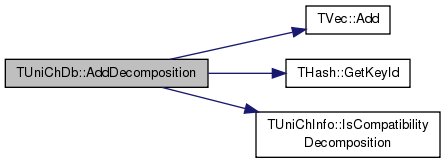
Definition at line 3103 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), TUniChInfo::decompOffset, decompositions, THash< TKey, TDat, THashFunc >::GetKeyId(), h, HangulLBase, HangulNCount, HangulSBase, HangulSCount, HangulTBase, HangulTCount, HangulVBase, and TUniChInfo::IsCompatibilityDecomposition().
Referenced by Decompose().
|
protected |
Definition at line 2585 of file unicode.h.
References TUniTrie< TItem_ >::Empty(), TUniTrie< TItem_ >::Get3GramRoot(), GetCat(), TUniTrie< TItem_ >::GetChild(), GetSbFlags(), TUniTrie< TItem_ >::Has1Gram(), TUniTrie< TItem_ >::Has2Gram(), IAssert, TUniTrie< TItem_ >::IsNodeTerminal(), sbExTrie, ucfSbATerm, ucfSbSep, ucfSbSp, ucfSbSTerm, and WbFindPrevNonIgnored().
Referenced by FindNextSentenceBoundary().

|
inline |
Definition at line 1276 of file unicode.h.
References caseFolding, charNames, THash< TKey, TDat, THashFunc >::Clr(), TUniCaseFolding::Clr(), TVec< TVal, TSizeTy >::Clr(), TStrPool::Clr(), decompositions, h, inverseDec, scripts, specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by LoadTxt().
| void TUniChDb::Compose | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3158 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), Assert, ccMax, TUniChInfo::ccStarter, TVec< TVal, TSizeTy >::Clr(), GetCombiningClass(), HangulLBase, HangulLCount, HangulSBase, HangulSCount, HangulTBase, HangulTCount, HangulVBase, HangulVCount, inverseDec, and TVec< TVal, TSizeTy >::Len().
Referenced by Compose(), TUnicode::Compose(), and DecomposeAndCompose().

|
inline |
Definition at line 1532 of file unicode.h.
References Compose().
| void TUniChDb::Decompose | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | compatibility, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3126 of file unicode.h.
References AddDecomposition(), TUniChInfo::ccStarter, TVec< TVal, TSizeTy >::Clr(), GetCombiningClass(), and TVec< TVal, TSizeTy >::Len().
Referenced by Decompose(), TUnicode::Decompose(), and DecomposeAndCompose().
|
inline |
Definition at line 1520 of file unicode.h.
References Decompose().
| void TUniChDb::DecomposeAndCompose | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | compatibility, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3148 of file unicode.h.
References TVec< TVal, TSizeTy >::Clr(), Compose(), Decompose(), and TVec< TVal, TSizeTy >::Len().
Referenced by DecomposeAndCompose(), and TUnicode::DecomposeAndCompose().

|
inline |
Definition at line 1542 of file unicode.h.
References DecomposeAndCompose().

| size_t TUniChDb::ExtractStarters | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| bool | clrDest = true |
||
| ) | const |
Definition at line 3215 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), TUniChInfo::ccStarter, TVec< TVal, TSizeTy >::Clr(), and GetCombiningClass().
Referenced by ExtractStarters(), and TUnicode::ExtractStarters().
|
inline |
Definition at line 1551 of file unicode.h.
References ExtractStarters().

|
inline |
Definition at line 1555 of file unicode.h.
References ExtractStarters(), and TVec< TVal, TSizeTy >::Len().

| bool TUniChDb::FindNextSentenceBoundary | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| size_t & | position | ||
| ) | const |
Definition at line 2636 of file unicode.h.
References CanSentenceEndHere(), GetSbFlags(), IAssert, IsPeekAheadSkippable, IsWbIgnored(), TestCurNext, TestPrevCurNext, Trans, ucfSbATerm, ucfSbClose, ucfSbLower, ucfSbNumeric, ucfSbSep, ucfSbSp, ucfSbSTerm, ucfSbUpper, WbFindNextNonIgnored(), and WbFindPrevNonIgnored().
Referenced by TUnicode::FindNextSentenceBoundary(), FindSentenceBoundaries(), and TestFindNextWordOrSentenceBoundary().

| bool TUniChDb::FindNextWordBoundary | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| size_t & | position | ||
| ) | const |
Definition at line 2483 of file unicode.h.
References GetWbFlags(), IAssert, IsWbIgnored(), TestCurNext, TestCurNext2, TestPrevCurNext, ucfWbALetter, ucfWbExtendNumLet, ucfWbKatakana, ucfWbMidLetter, ucfWbMidNum, ucfWbNumeric, WbFindNextNonIgnored(), and WbFindPrevNonIgnored().
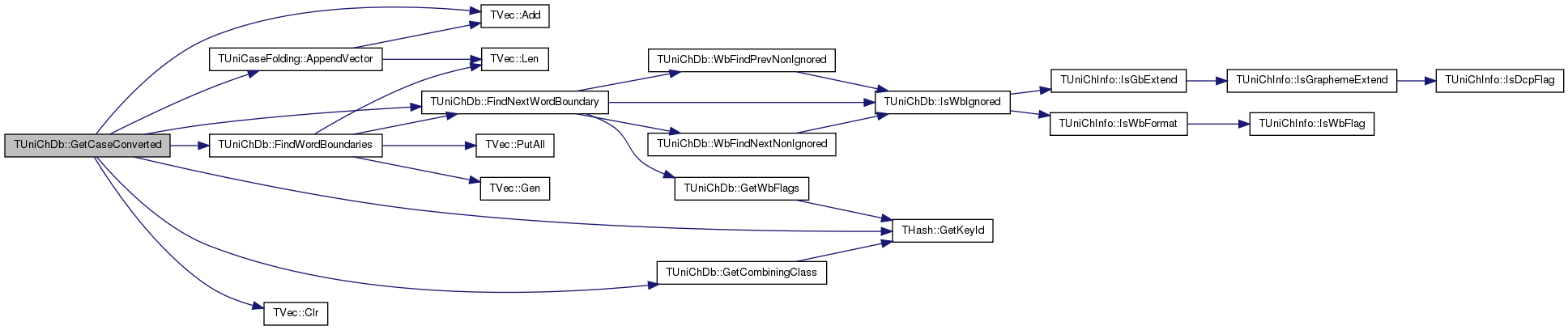
Referenced by TUnicode::FindNextWordBoundary(), FindWordBoundaries(), GetCaseConverted(), GetSimpleCaseConverted(), TestFindNextWordOrSentenceBoundary(), and ToSimpleCaseConverted().


| void TUniChDb::FindSentenceBoundaries | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TBoolV & | dest | ||
| ) | const |
Definition at line 2793 of file unicode.h.
References Assert, FindNextSentenceBoundary(), TVec< TVal, TSizeTy >::Gen(), TVec< TVal, TSizeTy >::Len(), and TVec< TVal, TSizeTy >::PutAll().
Referenced by TUnicode::FindSentenceBoundaries(), and TestFindNextWordOrSentenceBoundary().


| void TUniChDb::FindWordBoundaries | ( | const TSrcVec & | src, |
| const size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TBoolV & | dest | ||
| ) | const |
Definition at line 2561 of file unicode.h.
References Assert, FindNextWordBoundary(), TVec< TVal, TSizeTy >::Gen(), TVec< TVal, TSizeTy >::Len(), and TVec< TVal, TSizeTy >::PutAll().
Referenced by TUnicode::FindWordBoundaries(), GetCaseConverted(), and TestFindNextWordOrSentenceBoundary().

|
inlinestatic |
Definition at line 1304 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags(), and TestFindNextWordOrSentenceBoundary().

|
inlinestatic |
| void TUniChDb::GetCaseConverted | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest, | ||
| const TCaseConversion | how, | ||
| const bool | turkic, | ||
| const bool | lithuanian | ||
| ) | const |
Definition at line 2817 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), TUniCaseFolding::AppendVector(), Assert, TUniChInfo::ccAbove, ccLower, TUniChInfo::ccStarter, ccTitle, ccUpper, TVec< TVal, TSizeTy >::Clr(), FindNextWordBoundary(), FindWordBoundaries(), GetCombiningClass(), THash< TKey, TDat, THashFunc >::GetKeyId(), h, IAssert, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, TUniChInfo::simpleUpperCaseMapping, specialCasingLower, specialCasingTitle, and specialCasingUpper.
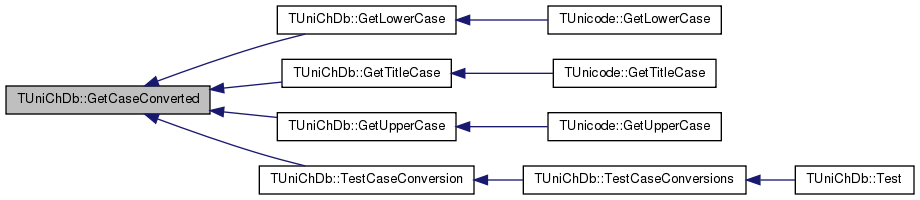
Referenced by GetLowerCase(), GetTitleCase(), GetUpperCase(), and TestCaseConversion().
|
inline |
Definition at line 1629 of file unicode.h.
References caseFolding, and TUniCaseFolding::Fold().
Referenced by GetCaseFolded(), and TUnicode::GetCaseFolded().


|
inline |
Definition at line 1632 of file unicode.h.
References GetCaseFolded().

|
inlinestatic |
|
inline |
Definition at line 1353 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by TUnicode::___UniFwd2(), and CanSentenceEndHere().


|
inline |
Definition at line 1331 of file unicode.h.
References charNames, TStrPool::GetCStr(), THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by TUnicode::GetCharName(), and GetCharNameS().


|
inline |
Definition at line 1332 of file unicode.h.
References GetCharName().
Referenced by TUnicode::GetCharNameS(), and PrintCharNames().


|
inline |
Definition at line 1399 of file unicode.h.
References TUniChInfo::ccStarter, THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by Compose(), Decompose(), ExtractStarters(), and GetCaseConverted().


|
inlinestatic |
|
inlinestatic |
Definition at line 1301 of file unicode.h.
Referenced by InitDerivedCoreProperties().

|
inlinestatic |
Definition at line 1302 of file unicode.h.
Referenced by InitLineBreaks().

|
inline |
Definition at line 1590 of file unicode.h.
References ccLower, and GetCaseConverted().
Referenced by TUnicode::GetLowerCase().


|
inline |
Definition at line 1593 of file unicode.h.
References GetLowerCase().
Referenced by GetLowerCase().


|
inlinestatic |
Definition at line 1309 of file unicode.h.
Referenced by TestComposition().

|
inlinestatic |
Definition at line 1303 of file unicode.h.
Referenced by InitPropList().

|
inline |
Definition at line 1359 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by CanSentenceEndHere(), FindNextSentenceBoundary(), and TestFindNextWordOrSentenceBoundary().


|
inline |
Definition at line 1323 of file unicode.h.
References TUniChInfo::script, and scriptUnknown.
Referenced by TUStr::GetChScriptId().
|
inline |
Definition at line 1324 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), GetScript(), h, and scriptUnknown.
Referenced by GetScript().

|
inline |
Definition at line 1322 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and scripts.
Referenced by TUStr::GetScriptId(), InitAfterLoad(), InitWordAndSentenceBoundaryFlags(), and LoadTxt().


|
inline |
Definition at line 1321 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKey(), and scripts.
Referenced by TUStr::GetScriptNm(), and TestWbFindNonIgnored().


|
inlinestatic |
Definition at line 1319 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().

|
inlinestatic |
Definition at line 1318 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().

|
inlinestatic |
Definition at line 1317 of file unicode.h.
Referenced by InitAfterLoad(), InitScripts(), and LoadTxt().

|
inlinestatic |
Definition at line 1300 of file unicode.h.
Referenced by InitScripts().

|
inlinestatic |
Definition at line 1308 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().

|
inlinestatic |
Definition at line 1307 of file unicode.h.
Referenced by TestFindNextWordOrSentenceBoundary().

| void TUniChDb::GetSimpleCaseConverted | ( | const TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| TVec< TDestCh > & | dest, | ||
| const bool | clrDest, | ||
| const TCaseConversion | how | ||
| ) | const |
Definition at line 3042 of file unicode.h.
References TVec< TVal, TSizeTy >::Add(), ccLower, ccTitle, ccUpper, TVec< TVal, TSizeTy >::Clr(), FindNextWordBoundary(), THash< TKey, TDat, THashFunc >::GetKeyId(), h, IAssert, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, and TUniChInfo::simpleUpperCaseMapping.
Referenced by GetSimpleLowerCase(), GetSimpleTitleCase(), and GetSimpleUpperCase().


|
inline |
Definition at line 1601 of file unicode.h.
References ccLower, and GetSimpleCaseConverted().
Referenced by TUnicode::GetSimpleLowerCase().

|
inline |
Definition at line 1604 of file unicode.h.
References GetSimpleLowerCase().
Referenced by GetSimpleLowerCase().


|
inline |
Definition at line 1603 of file unicode.h.
References ccTitle, and GetSimpleCaseConverted().
Referenced by TUnicode::GetSimpleTitleCase().


|
inline |
Definition at line 1606 of file unicode.h.
References GetSimpleTitleCase().
Referenced by GetSimpleTitleCase().


|
inline |
Definition at line 1602 of file unicode.h.
References ccUpper, and GetSimpleCaseConverted().
Referenced by TUnicode::GetSimpleUpperCase().


|
inline |
Definition at line 1605 of file unicode.h.
References GetSimpleUpperCase().
Referenced by GetSimpleUpperCase().


|
inlinestatic |
Definition at line 1297 of file unicode.h.
Referenced by InitSpecialCasing().

|
inline |
Definition at line 1354 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by TUnicode::GetSubCat().


|
inline |
Definition at line 1592 of file unicode.h.
References ccTitle, and GetCaseConverted().
Referenced by TUnicode::GetTitleCase().


|
inline |
Definition at line 1595 of file unicode.h.
References GetTitleCase().
Referenced by GetTitleCase().


|
inlinestatic |
|
inline |
Definition at line 1591 of file unicode.h.
References ccUpper, and GetCaseConverted().
Referenced by TUnicode::GetUpperCase().


|
inline |
Definition at line 1594 of file unicode.h.
References GetUpperCase().
Referenced by GetUpperCase().


|
inline |
Definition at line 1357 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.
Referenced by FindNextWordBoundary(), and TestFindNextWordOrSentenceBoundary().

|
inlinestatic |
Definition at line 1306 of file unicode.h.
Referenced by InitWordAndSentenceBoundaryFlags().

|
inlinestatic |
Definition at line 1305 of file unicode.h.
Referenced by TestFindNextWordOrSentenceBoundary().

|
protected |
Definition at line 1368 of file unicode.cpp.
References GetScriptByName(), GetScriptNameUnknown(), IAssert, and scriptUnknown.
Referenced by Load().


|
protected |
Definition at line 1007 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), FailR, GetDerivedCorePropsFn(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), h, IAssert, TUniChInfo::IsDcpFlag(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChDb::TSubcatHelper::ProcessComment(), TUniChDb::TSubcatHelper::SetCat(), TUniChInfo::SetDcpFlag(), TUniChDb::TSubcatHelper::TestCat(), ucfCompatibilityDecomposition, ucfDcpAlphabetic, ucfDcpDefaultIgnorableCodePoint, ucfDcpGraphemeBase, ucfDcpGraphemeExtend, ucfDcpIdContinue, ucfDcpIdStart, ucfDcpLowercase, ucfDcpMath, ucfDcpUppercase, ucfDcpXidContinue, and ucfDcpXidStart.
Referenced by LoadTxt().

|
protected |
Definition at line 1046 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChInfo::GetLineBreakCode(), GetLineBreakFn(), TUniChDb::TUcdFileReader::GetNextLine(), h, IAssert, TStr::Len(), TVec< TVal, TSizeTy >::Len(), TUniChInfo::LineBreak_Unknown, TUniChDb::TUcdFileReader::Open(), and TUniChDb::TUcdFileReader::ParseCodePointRange().
Referenced by LoadTxt().

|
protected |
Definition at line 950 of file unicode.cpp.
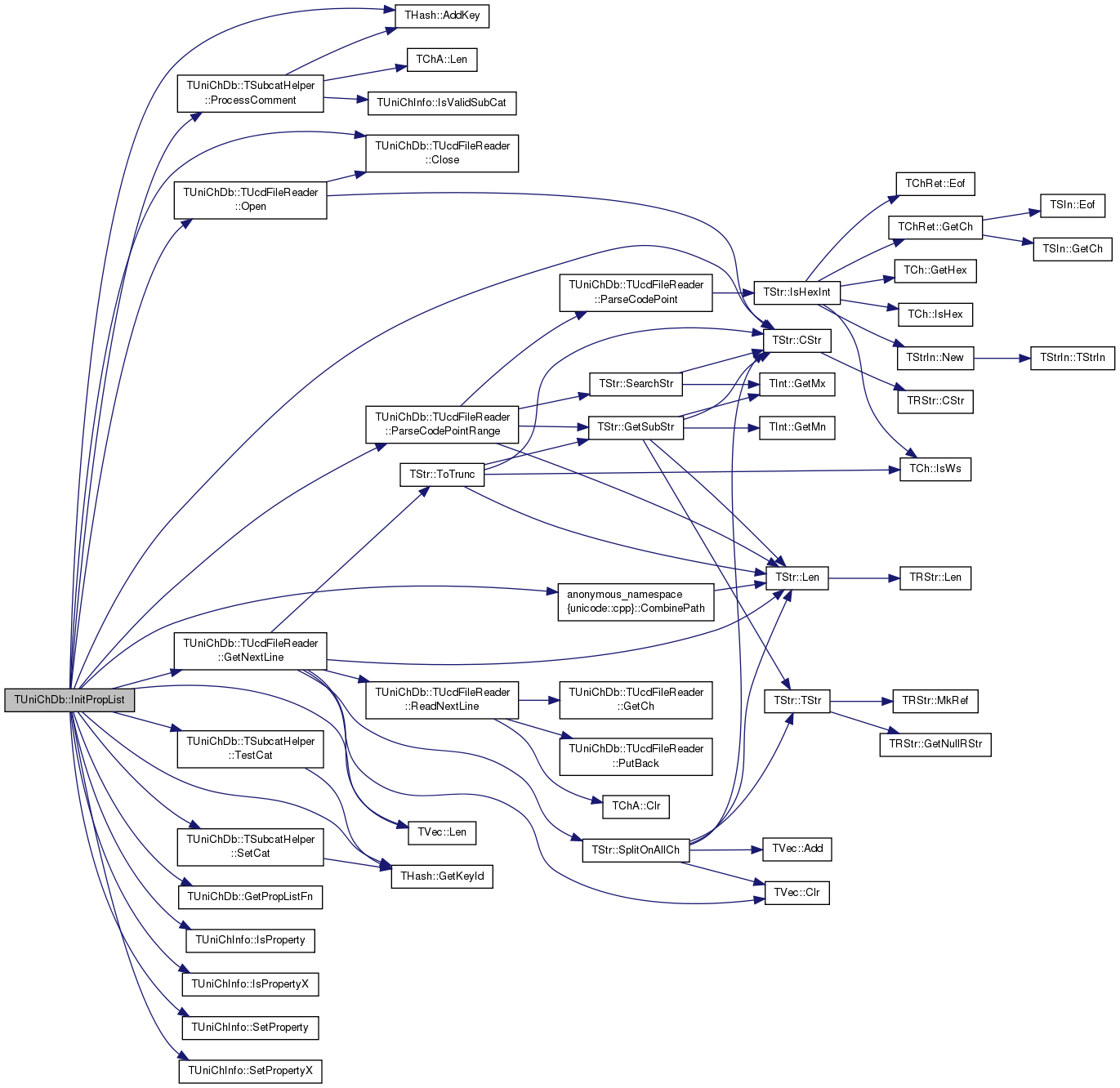
References THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), FailR, THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), GetPropListFn(), h, IAssert, TUniChInfo::IsProperty(), TUniChInfo::IsPropertyX(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChDb::TSubcatHelper::ProcessComment(), TUniChDb::TSubcatHelper::SetCat(), TUniChInfo::SetProperty(), TUniChInfo::SetPropertyX(), TUniChDb::TSubcatHelper::TestCat(), ucfPrAsciiHexDigit, ucfPrBidiControl, ucfPrDash, ucfPrDeprecated, ucfPrDiacritic, ucfPrExtender, ucfPrHexDigit, ucfPrHyphen, ucfPrIdeographic, ucfPrJoinControl, ucfPrLogicalOrderException, ucfPrNoncharacterCodePoint, ucfPrPatternSyntax, ucfPrPatternWhiteSpace, ucfPrQuotationMark, ucfPrSoftDotted, ucfPrSTerm, ucfPrTerminalPunctuation, ucfPrVariationSelector, ucfPrWhiteSpace, ucfPxIdsBinaryOperator, ucfPxIdsTrinaryOperator, ucfPxOtherAlphabetic, ucfPxOtherDefaultIgnorableCodePoint, ucfPxOtherGraphemeExtend, ucfPxOtherIdContinue, ucfPxOtherIdStart, ucfPxOtherLowercase, ucfPxOtherMath, ucfPxOtherUppercase, ucfPxRadical, and ucfPxUnifiedIdeograph.
Referenced by LoadTxt().

|
protected |
Definition at line 1073 of file unicode.cpp.
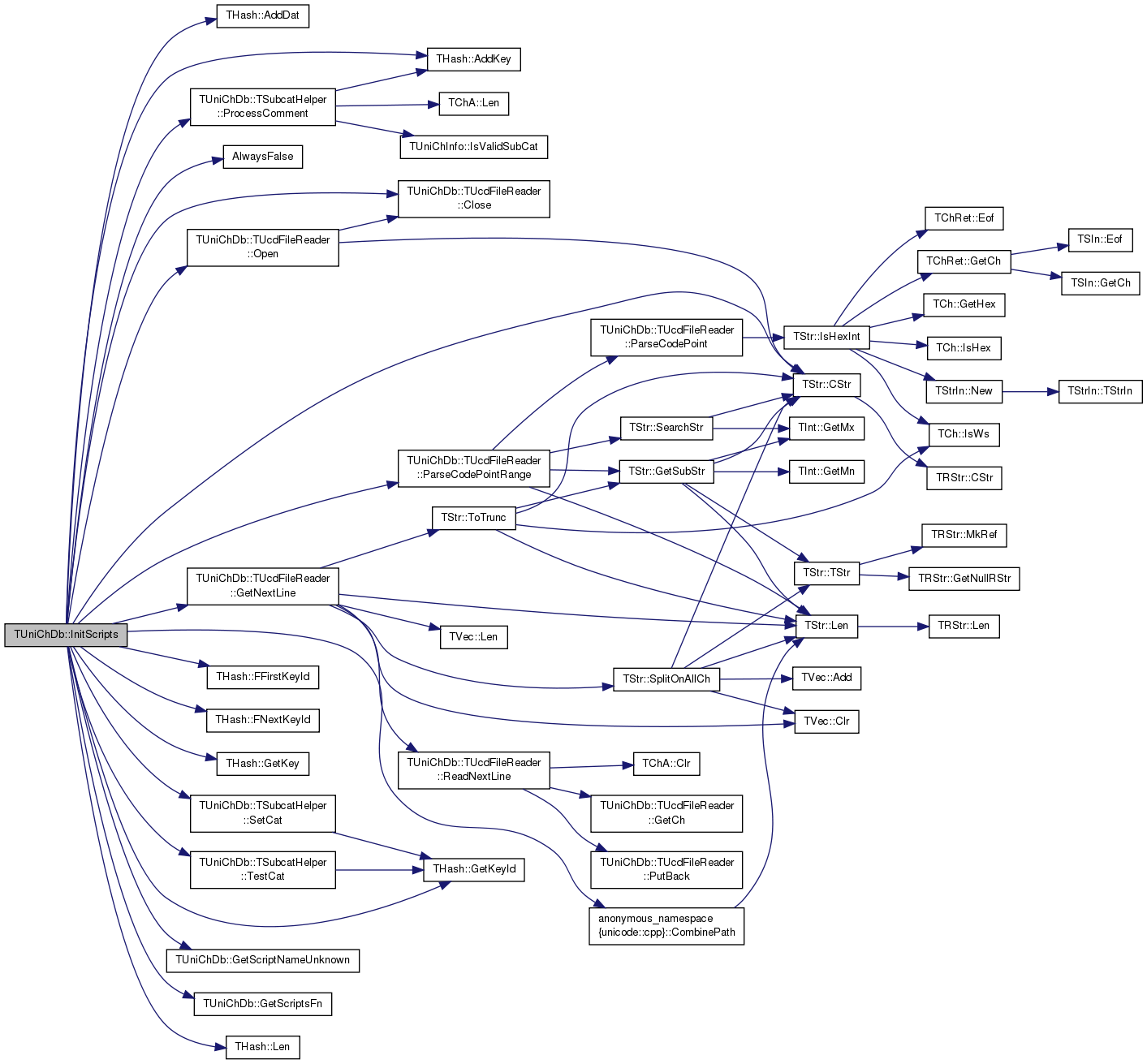
References THash< TKey, TDat, THashFunc >::AddDat(), THash< TKey, TDat, THashFunc >::AddKey(), AlwaysFalse(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), THash< TKey, TDat, THashFunc >::GetKey(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), GetScriptNameUnknown(), GetScriptsFn(), h, IAssert, THash< TKey, TDat, THashFunc >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChDb::TSubcatHelper::ProcessComment(), TUniChInfo::script, scripts, TUniChDb::TSubcatHelper::SetCat(), and TUniChDb::TSubcatHelper::TestCat().
Referenced by LoadTxt().

|
protected |
Definition at line 1225 of file unicode.cpp.
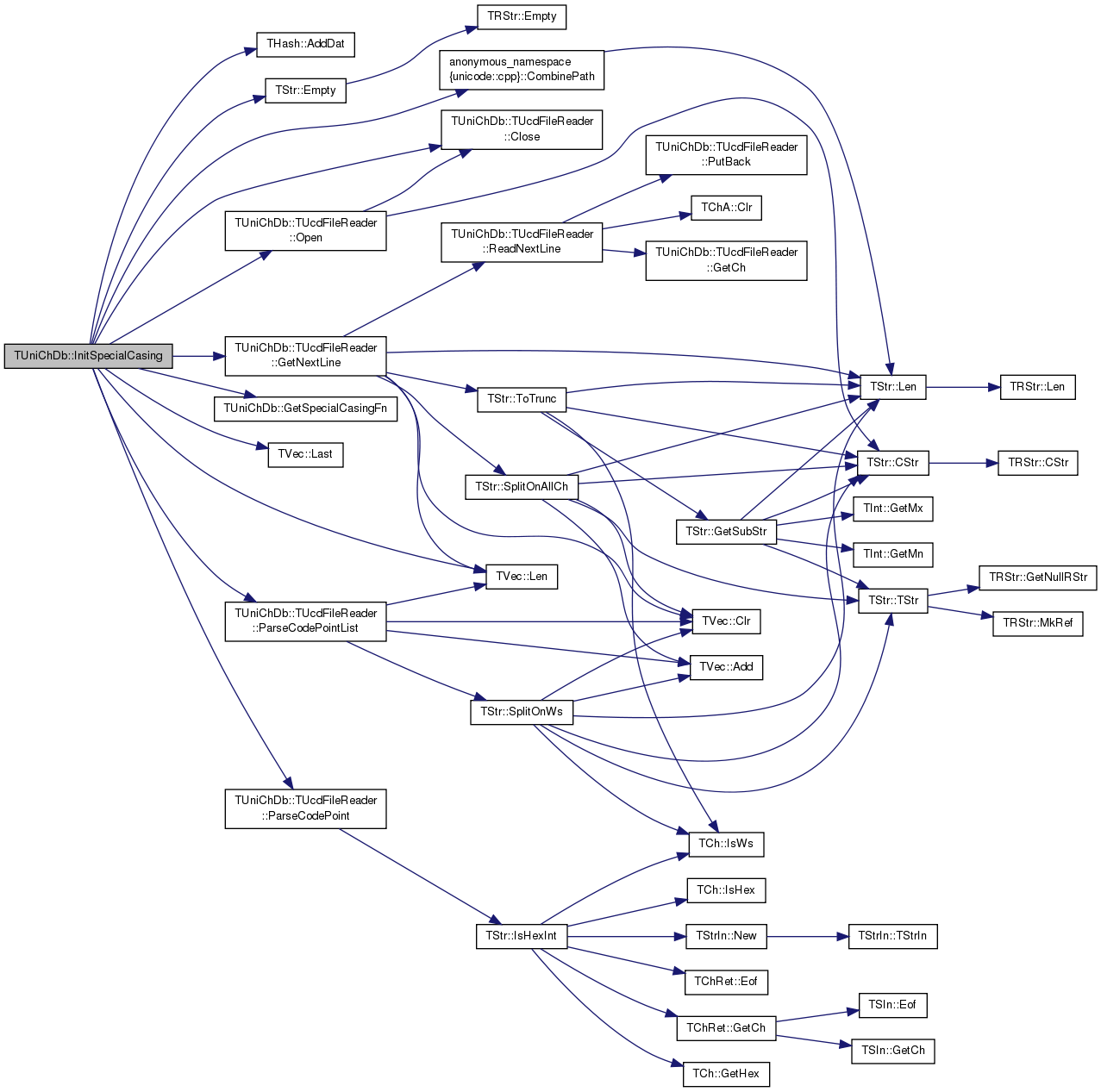
References THash< TKey, TDat, THashFunc >::AddDat(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::Empty(), TUniChDb::TUcdFileReader::GetNextLine(), GetSpecialCasingFn(), IAssert, TVec< TVal, TSizeTy >::Last(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePoint(), TUniChDb::TUcdFileReader::ParseCodePointList(), specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by LoadTxt().

|
protected |
Definition at line 1100 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), THash< TKey, TDat, THashFunc >::AddDat(), TUniChDb::TUcdFileReader::Close(), TUniChInfo::ClrWbAndSbFlags(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), Fail, FailR, THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), GetAuxiliaryDir(), THash< TKey, TDat, THashFunc >::GetDat(), THash< TKey, TDat, THashFunc >::GetKey(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), TUniChInfo::GetSbFlags(), TUniChInfo::GetSbFlagsStr(), GetScriptByName(), GetScriptNameHiragana(), GetScriptNameKatakana(), GetSentenceBreakPropertyFn(), TUniChInfo::GetWbFlags(), GetWordBreakPropertyFn(), h, IAssert, TUniChInfo::IsAlphabetic(), TUniChInfo::IsGraphemeExtend(), TUniChInfo::IsIdeographic(), THash< TKey, TDat, THashFunc >::IsKey(), TUniChInfo::IsLowercase(), TUniChInfo::IsSbFlag(), TUniChInfo::IsSTerminal(), TUniChInfo::IsUppercase(), TUniChInfo::IsWbFlag(), TUniChInfo::IsWhiteSpace(), TVec< TVal, TSizeTy >::Len(), TUniChInfo::lineBreak, TUniChInfo::LineBreak_ComplexContext, TUniChInfo::LineBreak_InfixNumeric, TUniChInfo::LineBreak_Numeric, TUniChInfo::LineBreak_Quotation, TVec< TVal, TSizeTy >::Merge(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePointRange(), TUniChInfo::script, TUniChInfo::SetSbFlag(), TUniChInfo::SetWbFlag(), TVec< TVal, TSizeTy >::Sort(), TUniChInfo::subCat, ucfCompatibilityDecomposition, ucfSbATerm, ucfSbClose, ucfSbFormat, ucfSbLower, ucfSbNumeric, ucfSbOLetter, ucfSbSep, ucfSbSp, ucfSbSTerm, ucfSbUpper, ucfWbALetter, ucfWbExtendNumLet, ucfWbFormat, ucfWbKatakana, ucfWbMidLetter, ucfWbMidNum, ucfWbNumeric, and anonymous_namespace{unicode.cpp}::VB.
Referenced by LoadTxt().


|
inline |
Definition at line 1350 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.

|
inline |
Definition at line 1383 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.

|
inline |
Definition at line 1358 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.

|
inline |
Definition at line 1392 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.

|
inline |
Definition at line 1356 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), and h.

|
inlinestaticprotected |
Definition at line 1419 of file unicode.h.
References TUniChInfo::IsGbExtend(), and TUniChInfo::IsWbFormat().
Referenced by FindNextSentenceBoundary(), FindNextWordBoundary(), TestFindNextWordOrSentenceBoundary(), TestWbFindNonIgnored(), WbFindCurOrNextNonIgnored(), WbFindNextNonIgnored(), WbFindNextNonIgnoredS(), and WbFindPrevNonIgnored().


|
inlineprotected |
Definition at line 1420 of file unicode.h.
References THash< TKey, TDat, THashFunc >::GetKeyId(), h, and IsWbIgnored().
Referenced by IsWbIgnored().


|
inline |
Definition at line 1285 of file unicode.h.
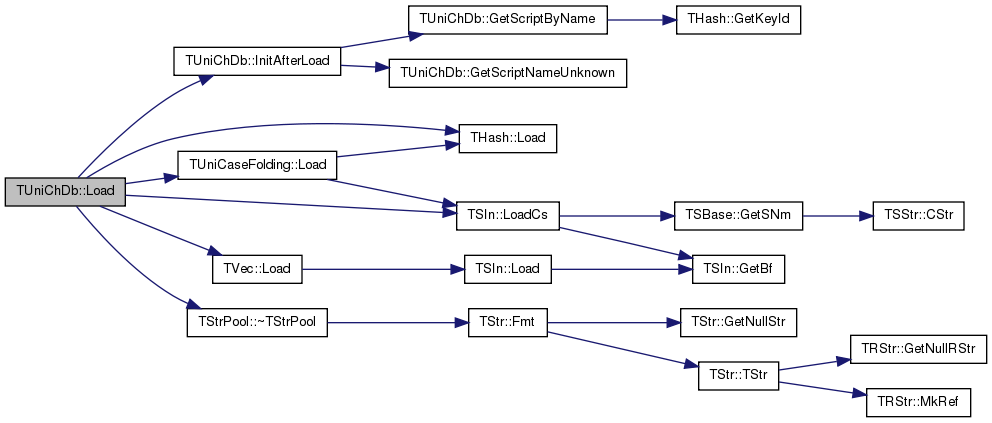
References caseFolding, charNames, decompositions, h, InitAfterLoad(), inverseDec, THash< TKey, TDat, THashFunc >::Load(), TUniCaseFolding::Load(), TVec< TVal, TSizeTy >::Load(), TSIn::LoadCs(), scripts, specialCasingLower, specialCasingTitle, specialCasingUpper, and TStrPool::~TStrPool().
Referenced by LoadBin(), Test(), and TUniChDb().

|
inline |
Definition at line 1291 of file unicode.h.
References Load(), and TFIn::New().
Referenced by TUnicode::TUnicode().

| void TUniChDb::LoadTxt | ( | const TStr & | basePath | ) |
Definition at line 1249 of file unicode.cpp.
References THash< TKey, TDat, THashFunc >::AddDat(), THash< TKey, TDat, THashFunc >::AddKey(), TStrPool::AddStr(), caseFolding, TUniChInfo::ccInvalid, TUniChInfo::ccStarter, charNames, TUniChInfo::chCat, TUniChInfo::chSubCat, TUniChDb::TUcdFileReader::Close(), Clr(), TUniChInfo::combClass, anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), TUniChInfo::decompOffset, decompositions, TStr::Empty(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), TUniChInfo::flags, THash< TKey, TDat, THashFunc >::FNextKeyId(), GetCaseFoldingFn(), GetCompositionExclusionsFn(), THash< TKey, TDat, THashFunc >::GetDat(), THash< TKey, TDat, THashFunc >::GetKey(), THash< TKey, TDat, THashFunc >::GetKeyId(), TUniChDb::TUcdFileReader::GetNextLine(), GetScriptByName(), GetScriptNameUnknown(), GetUnicodeDataFn(), h, HangulSBase, HangulSCount, IAssert, IAssertR, TUniChInfo::InitAfterLoad(), InitDerivedCoreProperties(), InitLineBreaks(), InitPropList(), InitScripts(), InitSpecialCasing(), InitWordAndSentenceBoundaryFlags(), inverseDec, TUniChInfo::IsCompatibilityDecomposition(), TUniChInfo::IsCompositionExclusion(), TStr::IsInt(), THash< TKey, TDat, THashFunc >::IsKey(), THash< TKey, TDat, THashFunc >::Len(), TStr::Len(), TVec< TVal, TSizeTy >::Len(), TUniCaseFolding::LoadTxt(), LoadTxt_ProcessDecomposition(), TUCh::Mn, TUCh::Mx, TUniChInfo::nameOffset, TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePoint(), TUniChInfo::script, scriptUnknown, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, TUniChInfo::simpleUpperCaseMapping, and ucfCompositionExclusion.
Referenced by Test().


|
protected |
Definition at line 937 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), TVec< TVal, TSizeTy >::AddV(), TUniChInfo::decompOffset, decompositions, TStr::Empty(), TUniChInfo::flags, TStr::GetSubStr(), IAssert, TStr::Len(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::ParseCodePointList(), TStr::SearchCh(), TStr::ToTrunc(), and ucfCompatibilityDecomposition.
Referenced by LoadTxt().


|
inline |
Definition at line 1336 of file unicode.h.
References TStr::CStr(), and GetCharNameS().

|
inline |
Definition at line 1342 of file unicode.h.
References PrintCharNames().
Referenced by PrintCharNames().


|
inline |
Definition at line 1280 of file unicode.h.
References caseFolding, charNames, decompositions, h, inverseDec, THash< TKey, TDat, THashFunc >::Save(), TUniCaseFolding::Save(), TVec< TVal, TSizeTy >::Save(), TStrPool::Save(), TSOut::SaveCs(), scripts, specialCasingLower, specialCasingTitle, and specialCasingUpper.
Referenced by SaveBin(), and Test().

| void TUniChDb::SaveBin | ( | const TStr & | fnBinUcd | ) |
Definition at line 1362 of file unicode.cpp.
References TFOut::New(), and Save().
|
inline |
Definition at line 1490 of file unicode.h.
References TUniTrie< TItem_ >::Add(), and sbExTrie.
Referenced by SbEx_Add(), SbEx_AddMulti(), and SbEx_AddUtf8().


|
inline |
Definition at line 1492 of file unicode.h.
References TVec< TVal, TSizeTy >::Gen(), TStr::Len(), and SbEx_Add().
|
inline |
Definition at line 1495 of file unicode.h.
References TVec< TVal, TSizeTy >::Len(), SbEx_Add(), SbEx_AddUtf8(), and TStr::SplitOnAllCh().
Referenced by SbEx_SetStdEnglish().
|
inline |
Definition at line 1494 of file unicode.h.
References TUniCodec::DecodeUtf8(), and SbEx_Add().
Referenced by SbEx_AddMulti().

|
inline |
Definition at line 1489 of file unicode.h.
References TUniTrie< TItem_ >::Clr(), and sbExTrie.
Referenced by TUnicode::ClrSentenceBoundaryExceptions(), and SbEx_SetStdEnglish().


|
inline |
Definition at line 1499 of file unicode.h.
References SbEx_AddMulti(), and SbEx_Clr().
Referenced by TUnicode::UseEnglishSentenceBoundaryExceptions().

| void TUniChDb::Test | ( | const TStr & | basePath | ) |
Definition at line 1377 of file unicode.cpp.
References caseFolding, anonymous_namespace{unicode.cpp}::CombinePath(), TFile::Exists(), GetBinFn(), Load(), LoadTxt(), TFIn::New(), TFOut::New(), Save(), TUniCaseFolding::Test(), TestCaseConversions(), TestComposition(), TestFindNextWordOrSentenceBoundary(), TestWbFindNonIgnored(), and TUniChDb().

|
protected |
Definition at line 825 of file unicode.cpp.
References ccLower, ccTitle, ccUpper, GetCaseConverted(), IAssert, TVec< TVal, TSizeTy >::Len(), and TUniChDb::TUcdFileReader::ParseCodePointList().
Referenced by TestCaseConversions().

|
protected |
Definition at line 853 of file unicode.cpp.
References TestCaseConversion().
Referenced by Test().

|
protected |
Definition at line 745 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), THash< TKey, TDat, THashFunc >::AddKey(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), THash< TKey, TDat, THashFunc >::FNextKeyId(), THash< TKey, TDat, THashFunc >::GetKey(), TUniChDb::TUcdFileReader::GetNextLine(), GetNormalizationTestFn(), h, IAssert, THash< TKey, TDat, THashFunc >::IsKey(), TVec< TVal, TSizeTy >::Len(), NFC_, NFD_, NFKC_, NFKD_, TUniChDb::TUcdFileReader::Open(), and TUniChDb::TUcdFileReader::ParseCodePointList().
Referenced by Test().

|
protected |
Definition at line 649 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), TVec< TVal, TSizeTy >::AddV(), AlwaysFalse(), TUniChDb::TUcdFileReader::Close(), anonymous_namespace{unicode.cpp}::CombinePath(), TStr::CStr(), Fail, FailR, FindNextSentenceBoundary(), FindNextWordBoundary(), FindSentenceBoundaries(), FindWordBoundaries(), TVec< TVal, TSizeTy >::Gen(), GetAuxiliaryDir(), TUniChDb::TUcdFileReader::GetNextLine(), GetSbFlags(), TUniChInfo::GetSbFlagsStr(), GetSentenceBreakTestFn(), TRnd::GetUniDevInt(), GetWbFlags(), TUniChInfo::GetWbFlagsStr(), GetWordBreakTestFn(), IAssert, IsWbIgnored(), TVec< TVal, TSizeTy >::Len(), TUniChDb::TUcdFileReader::Open(), TUniChDb::TUcdFileReader::ParseCodePoint(), and TVec< TVal, TSizeTy >::PutAll().
Referenced by Test().


|
protected |
Definition at line 579 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Gen(), IAssert, IsWbIgnored(), TVec< TVal, TSizeTy >::Len(), WbFindCurOrNextNonIgnored(), WbFindNextNonIgnored(), and WbFindPrevNonIgnored().
|
protected |
Definition at line 619 of file unicode.cpp.
References TVec< TVal, TSizeTy >::Add(), TStr::CStr(), THash< TKey, TDat, THashFunc >::FFirstKeyId(), TUniChInfo::flags, THash< TKey, TDat, THashFunc >::FNextKeyId(), TVec< TVal, TSizeTy >::Gen(), THash< TKey, TDat, THashFunc >::GetKey(), GetScriptName(), h, IsWbIgnored(), TVec< TVal, TSizeTy >::Len(), TUniChInfo::properties, TUniChInfo::propertiesX, TUniChInfo::script, and TVec< TVal, TSizeTy >::Sort().
Referenced by Test().

|
inline |
Definition at line 1636 of file unicode.h.
References caseFolding, and TUniCaseFolding::FoldInPlace().
Referenced by TUnicode::ToCaseFolded().


|
inline |
Definition at line 1637 of file unicode.h.
References ToCaseFolded().
Referenced by ToCaseFolded().


| void TUniChDb::ToSimpleCaseConverted | ( | TSrcVec & | src, |
| size_t | srcIdx, | ||
| const size_t | srcCount, | ||
| const TCaseConversion | how | ||
| ) | const |
Definition at line 3072 of file unicode.h.
References ccLower, ccTitle, ccUpper, FindNextWordBoundary(), THash< TKey, TDat, THashFunc >::GetKeyId(), h, IAssert, TUniChInfo::simpleLowerCaseMapping, TUniChInfo::simpleTitleCaseMapping, and TUniChInfo::simpleUpperCaseMapping.
Referenced by ToSimpleLowerCase(), ToSimpleTitleCase(), and ToSimpleUpperCase().


|
inline |
Definition at line 1610 of file unicode.h.
References ccLower, and ToSimpleCaseConverted().
Referenced by TUnicode::ToSimpleLowerCase().


|
inline |
Definition at line 1613 of file unicode.h.
References ToSimpleLowerCase().
Referenced by ToSimpleLowerCase().


|
inline |
Definition at line 1611 of file unicode.h.
References ccTitle, and ToSimpleCaseConverted().
Referenced by TUnicode::ToSimpleTitleCase().


|
inline |
Definition at line 1614 of file unicode.h.
References ToSimpleTitleCase().
Referenced by ToSimpleTitleCase().


|
inline |
Definition at line 1609 of file unicode.h.
References ccUpper, and ToSimpleCaseConverted().
Referenced by TUnicode::ToSimpleUpperCase().


|
inline |
Definition at line 1612 of file unicode.h.
References ToSimpleUpperCase().
Referenced by ToSimpleUpperCase().


|
inlineprotected |
Definition at line 1422 of file unicode.h.
References IsWbIgnored().
Referenced by TestWbFindNonIgnored().


|
inlineprotected |
Definition at line 1425 of file unicode.h.
References IsWbIgnored().
Referenced by FindNextSentenceBoundary(), FindNextWordBoundary(), and TestWbFindNonIgnored().

|
inlineprotected |
Definition at line 1429 of file unicode.h.
References IsWbIgnored().

|
inlineprotected |
Definition at line 1434 of file unicode.h.
References IsWbIgnored().
Referenced by CanSentenceEndHere(), FindNextSentenceBoundary(), FindNextWordBoundary(), and TestWbFindNonIgnored().

|
friend |
| TUniCaseFolding TUniChDb::caseFolding |
Definition at line 1268 of file unicode.h.
Referenced by Clr(), GetCaseFolded(), Load(), LoadTxt(), Save(), Test(), and ToCaseFolded().
| TStrPool TUniChDb::charNames |
| TIntV TUniChDb::decompositions |
Definition at line 1266 of file unicode.h.
Referenced by AddDecomposition(), Clr(), Load(), LoadTxt(), LoadTxt_ProcessDecomposition(), and Save().
| THash<TInt, TUniChInfo> TUniChDb::h |
Definition at line 1263 of file unicode.h.
Referenced by AddDecomposition(), Clr(), GetCaseConverted(), GetCat(), GetCharName(), GetCombiningClass(), GetSbFlags(), GetScript(), GetSimpleCaseConverted(), GetSubCat(), GetWbFlags(), InitDerivedCoreProperties(), InitLineBreaks(), InitPropList(), InitScripts(), InitWordAndSentenceBoundaryFlags(), IsGetChInfo(), IsPrivateUse(), IsSbFlag(), IsSurrogate(), IsWbFlag(), IsWbIgnored(), Load(), LoadTxt(), Save(), TUniChDb::TSubcatHelper::SetCat(), TUniChDb::TSubcatHelper::TestCat(), TestComposition(), TestWbFindNonIgnored(), and ToSimpleCaseConverted().
Definition at line 1461 of file unicode.h.
Referenced by CanSentenceEndHere(), SbEx_Add(), SbEx_Clr(), and SbEx_Set().
| TStrIntH TUniChDb::scripts |
Definition at line 1265 of file unicode.h.
Referenced by Clr(), GetScriptByName(), GetScriptName(), InitScripts(), Load(), and Save().
| int TUniChDb::scriptUnknown |
Definition at line 1272 of file unicode.h.
Referenced by GetScript(), InitAfterLoad(), and LoadTxt().
| TIntIntVH TUniChDb::specialCasingLower |
Definition at line 1271 of file unicode.h.
Referenced by Clr(), GetCaseConverted(), InitSpecialCasing(), Load(), and Save().
| TIntIntVH TUniChDb::specialCasingTitle |
Definition at line 1271 of file unicode.h.
Referenced by Clr(), GetCaseConverted(), InitSpecialCasing(), Load(), and Save().
| TIntIntVH TUniChDb::specialCasingUpper |
Definition at line 1271 of file unicode.h.
Referenced by Clr(), GetCaseConverted(), InitSpecialCasing(), Load(), and Save().
 1.8.7
1.8.7